PyTorch
Distributed Training
Process Communication
When spawning multiple processes for distributed training, there are some terminology to be aware of. The world size is the total number of processes used in training. In DDP, this is typically the number of GPUs as you are using one process per GPU. The rank is the unique ID of a process among the processes and spans 0, ..., world_size - 1. Ranks are important to coordinate inter process communication.
A launcher from scratch (which you wouldn't do in practice) would look something like:
"""run.py:"""
#!/usr/bin/env python
import os
import sys
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank, size):
""" Distributed function to be implemented later. """
pass
def init_process(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
if __name__ == "__main__":
world_size = 2
processes = []
if "google.colab" in sys.modules:
print("Running in Google Colab")
mp.get_context("spawn")
else:
mp.set_start_method("spawn")
for rank in range(world_size):
p = mp.Process(target=init_process, args=(rank, world_size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
In point-to-point communication, a process transfers data to another process. This can be done using send and recv for blocking communication and isend and irecv for non-blocking communication in the torch.distributed package. Point-to-point communication is usually used when more fine-grained control over process communication is desired.
In most cases, distributed training employs collective communication, which involve communication across all processes within a group. A group is a subset of all processes and can be created by passing a list of ranks to dist.new_group(group). By default collective communication acts on all processes in the world, but you can specify a particular group, e.g. dist.all_reduce(tensor, op, group).
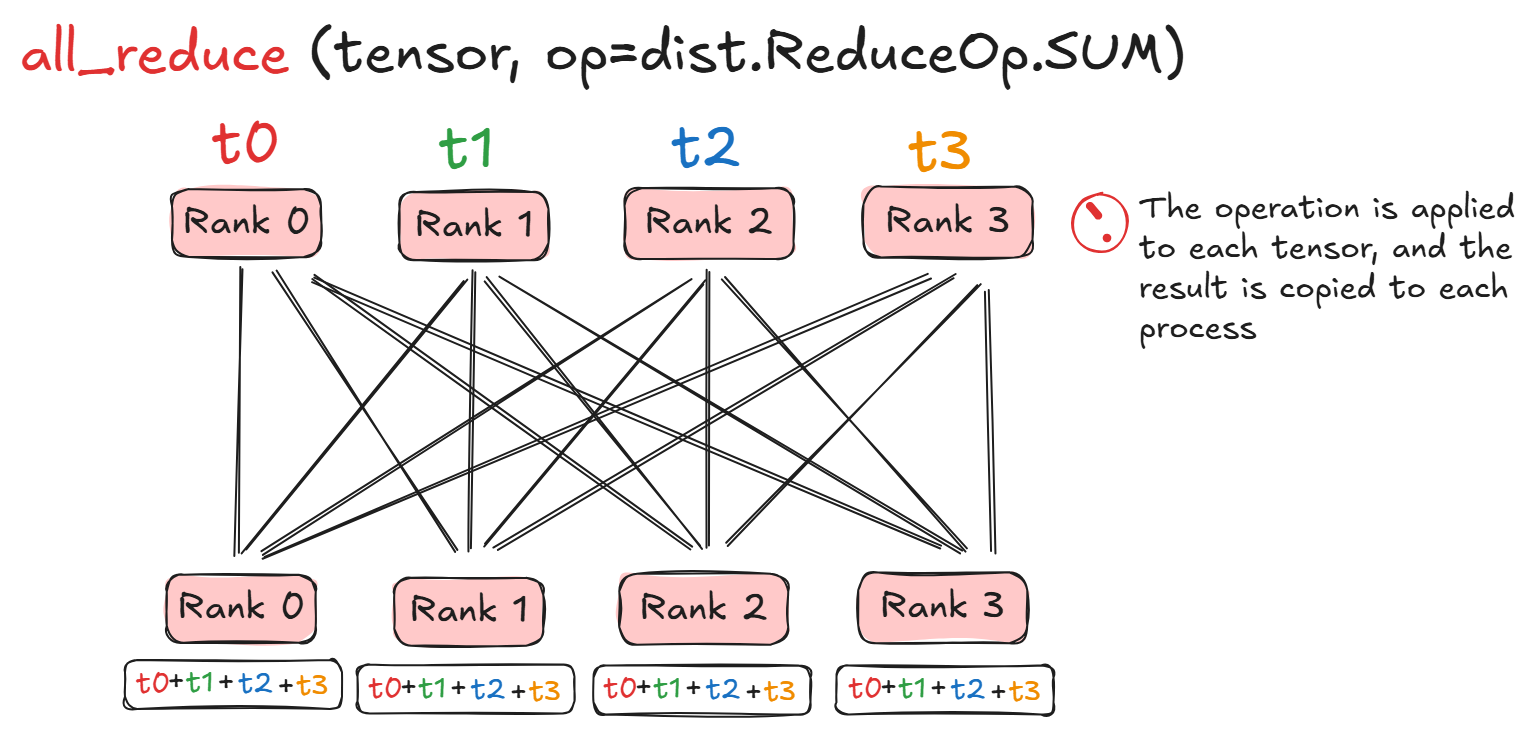
The collective function all_reduce as an example performs the operation across all tensors and sends the result to each process:
Some other important collectives to remember:
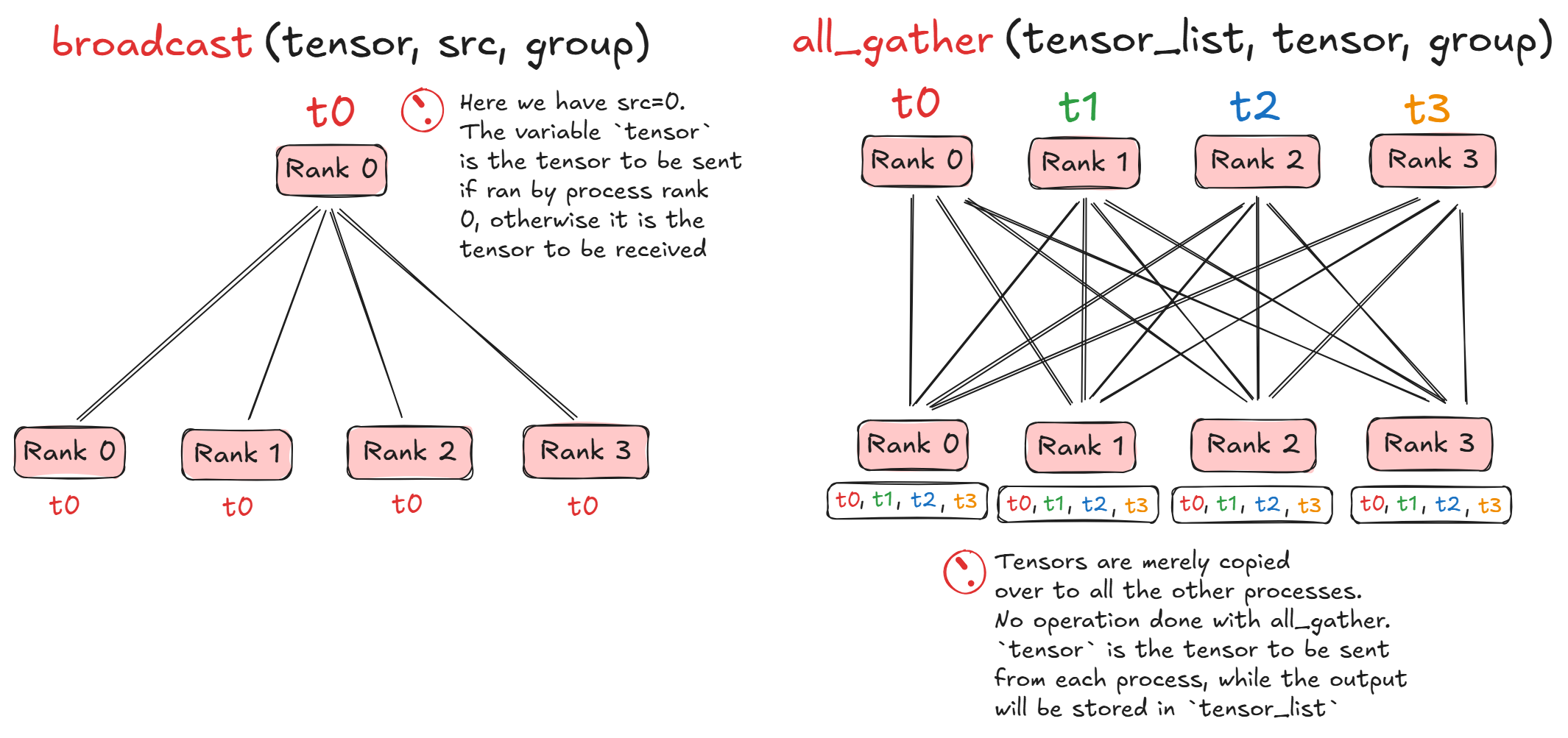
dist.broadcast(tensor, src, group)- copiestensorfromsrcto all processesdist.all_gather(tensor_list, tensor, group)- copiestensorfrom all processes totensor_liston all processes
There are many more collectives with diverse functions, some that don't do any operations except copy tensors, some that have distinct communication patterns such as:
dist.reduce(tensor, dst, op, group)- appliesopto eachtensorand stores result in process with rankdst(anint)dist.scatter(tensor, scatter_list, src, group)- copies theitensorscatter_list[i]to the ith processdist.gather(tensor, gather_list, dst, group)- copiestensorfrom all processes to process with rankdstdist.barrier(group)- blocks all processes ingroupuntil each one has entered this function
PyTorch provides many commutative operators for element wise operations (this is only a subset):
dist.ReduceOp.SUMdist.ReduceOp.PRODUCTdist.ReduceOp.MAXdist.ReduceOp.MINdist.ReduceOp.BANDdist.ReduceOp.BORdist.ReduceOp.BXORdist.ReduceOp.PREMUL_SUM
DDP Internals
What happens under the hood with DDP?
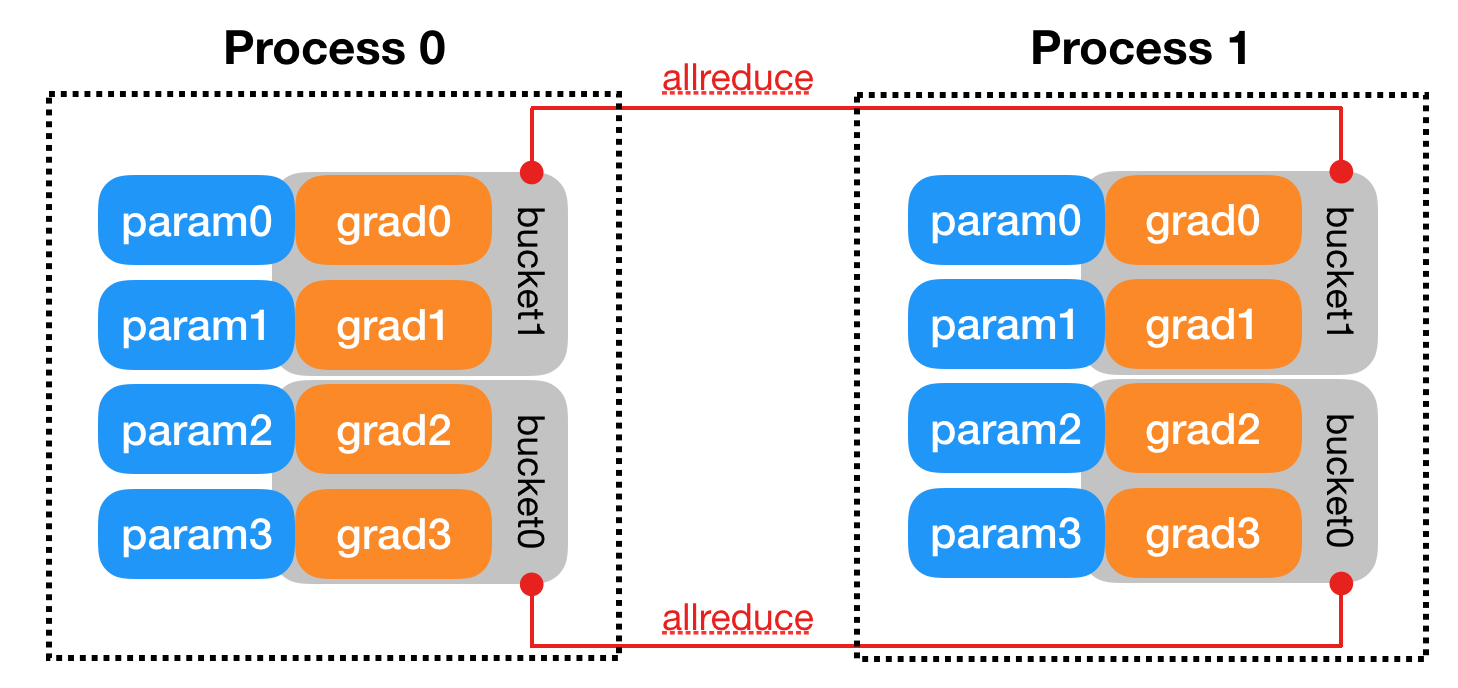
DDP adds autograd hooks to each parameter to track when gradients are available. Parameters gradients are organized into buckets and during backpropagation each bucket is all reduced to get the mean gradients for that bucket across all processes.
When you wrap ddp_model = DDP(model, device_ids=[rank]) the DDP constructor takes the reference to the local module and broadcasts its state_dict() from rank 0 to all other processes to ensure models start from the same state. Then each DDP process creates a local Reducer which handles gradient synchronization during backprop.
The Reducer organizes parameter gradients into buckets and reduces one bucket at a time. The mapping from parameter gradients to bucket is determined at construction, with bucket size configurable via bucket_cap_mb. The buckets also go in reverse order of Model.parameters() to follow the availability of gradients during the backward pass. The Reducer also registers autograd hooks with one hook per parameter, so when a gradient is ready it fires the hook and DDP will know.
During the backward pass, the autograd hooks setup during construction fires to trigger gradient synchronization. When gradients in one bucket all fire and DDP knows its ready, the Reducer starts an allreduce on the bucket to calculate mean gradient across all processes. When all buckets are ready, DDP blocks for all allreduce to finish. Finally, the averaged gradients are written to param.grad for the final weight update. All processes should share the same gradients at this point after the allreduce.
Communication Backends
Why do we have different backends? DDP and torch.distributed are merely abstractions, and the backend specifies how the processes actually communicate with one another. For instance, gloo is a great backend because it implements all point to point communication and collectives on CPU, and all collectives on GPU.
DDP is an API that orchestrates when you sync, the backend decides how you sync.
By default PyTorch comes with gloo and nccl, but mpi is not (you need to manually install).
Which backend to use:
- Use
ncclbackend for distributed training with CUDA GPU. (NCCL stands for NVIDIA Collective Communication Library) - Use
gloobackend for distributed training with CPU. - Use
xcclbackend for distributed training with XPU GPU.
Training Script
In practice, you will have the global process of rank 0 own the experiment (e.g. do logging) while the other ranks do gradient computation.
The overall steps are as follows for distributed code:
- Spawn N processes for N GPUs
- Create a process group (
dist.init_process_group) - Use
DistributedSampler - Wrap model with
DDP - Close process group (
dist.destroy_process_group)
First, you must call mp.spawn() (typically in main) to spawn the multiple processes. At this point they are not aware of each other and are not assigned a GPU. Then before instantiating the model, each process must call:
def init_distributed(local_rank, world_size):
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
torch.cuda.set_device(local_rank)
dist.init_process_group(backend="nccl", rank=rank, world_size=world_size)
The call dist.init_process_group() is a blocking point with processes blocked until all processes join the group.
torch.cuda.set_device(local_rank) ensures that each process has its exclusive GPU. Note that instead of doing device = "cuda" you will also have to specify the device ordinal either using torch.cuda.set_device(local_rank) or having device = torch.device("cuda", local_rank) which you pass around.
A torch.device contains a device type (["cuda", "cpu", "mps"]), and an optional device ordinal for the device type. If only the type is specified e.g. torch.device('cuda') then the implicit index is the current device from torch.cuda.current_device() which by default is the 0 device.
You can construct a device with the optional device ordinals:
# create device with device ordinal 0
torch.device('cuda', 0)
# same
torch.device('cuda:0')
# same if torch.accelerator.current_accelerator() == cuda
torch.device(0)
Methods taking device take both the object or the string. As you know, torch.device objects can also be substituted with a string, so tensor.to(torch.device('cuda:1')) is equivalent to tensor.to('cuda:1').
For using the DistributedSampler in the dataloader, make sure that shuffle=False is set in the dataloader. With DistributedSampler you must call sampler.set_epoch(epoch) at the beginning of each epoch for index shuffling. Note also that indices may be duplicated if the number of samples is not perfectly divisible by number of processes (because each process needs to get the same number of samples).
When using torchmetrics.Metric in a distributed setting (with a defined dist_reduce_fx), note that all ranks must call compute() to sync their results even if rank 0 is the only one that logs those metrics. Otherwise you must call with sync_on_compute=False.
It is also important to keep the overhead of synchronization low, so only calling synchronization code when necessary. For instance, with the training loop, it is often not necessary to all reduce the train loss across the ranks. However, for early stopping it is important that all ranks have the same validation loss, therefore it is recommended to all reduce the validation loss every epoch (which is not very frequent).
Avoid using num_workers > 0 for DDP dataloading. It causes hard to debug OOM errors and processes getting SIGKILL.